

Your comments are invited on a proposal to encode the script ‘prevalent’/’in vogue’ (pracalita) in Nepal since the late fourteenth century, and which since the Shah period has continued in use in the scribal and print culture of the Newars. The proposal under discussion was submitted a month ago by Anshuman Pandey to the international standards body for character sets, WG2 under JTC1 of the ISO. Download it here:
Anshuman Pandey. ‘Proposal to Encode the Newar Script in ISO/IEC 10646’. ISO/IEC JTC1/SC2/WG2 proposal N4184 [PDF]. January 5, 2012. [Supersedes N4038, ‘Preliminary Proposal to Encode the Prachalit Nepal Script’]
Anyone can submit a proposal for consideration by WG2. However, this is not a trivial process; documents need to comply with the group’s requirements, and if I observe correctly, there are very few competing complete proposals for historic scripts. No proposal has come from the Nepalese government, Newar culture having little, if any, official status in the Shah and post-Shah nation-state. The proposal under discussion (hereafter “N4184”) is that of a private individual, in collaboration with the Script Encoding Initiative at Berkeley. Mr. Pandey has graciously agreed to consider informed feedback on his proposal, which I hope will be incorporated into future documents submitted to WG2. It is in this constructive spirit that your feedback is requested; anyone may add comments via the form the end of this post.
1. Intended scope of these comments: focus on repertoire
The present discussion should focus on the completeness and accuracy of the glyph repertoire represented in the present proposal. Matters such as the proposed name and classification of the script, the description of interaction between glyphs (e.g. conjunct formation, §4.8.1), issues related to other Nepalese or Indic scripts (except where strictly relevant) and so on should notbe discussed here. If there is sufficient interest, these matters can be addressed in separate posting(s). Here I will offer some of my own preliminary, informal feedback on the proposal, on which comments are also welcome.
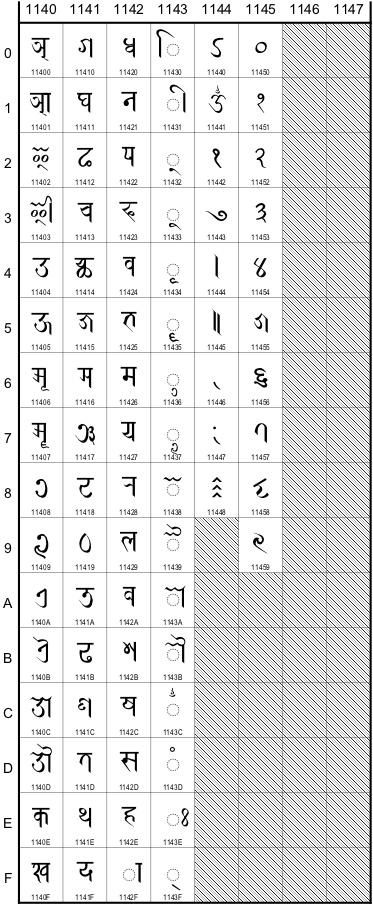
N4184 aims to “encode a core set of Newar characters” (p.17). This invites the question of how “core” should be defined. I will not discuss this in depth, other to say that the standard should include those characters which are most common and most useful in this form of writing. Specifically, I propose that the characters depicted in Figs.6 and 7 below should be part of the standard. This is the repertoire proposed in N4184:

Continue reading “Nepalese Script in Unicode, 1: JTC1/WG2 N4184 Open Thread”












